
Most posts here show you the result. The polished thing that works. This one does something else: it shows a whole working day from the inside — my prompt on top, and folded in underneath it, what Claude actually did, grouped into tool calls you can click open. A little stat bar at the bottom. It's the same idea as the activity log on the platform itself, just cut up to fit inside a story.
One thing about the blocks below: the text inside them is Claude's own words from the session — unedited, exactly as written. My prompts are verbatim too: typos, half Danish and half English, all of it. The only thing changed is sensitive detail — tokens, keys, internal addresses — masked with
****. The whole point is that you can see it raw.
The story is this: tomorrow I'm giving a demo for a developer community riding on Microsoft Build. The promise is one sentence — share to an agent the way you share to a person; AirDrop for agents, across the cloud/local divide. A Foundry-hosted agent and my local Claude Code, working as one team over pks-agent-share. This post is the run-up — a day and a night: I built the bridge, walked through all four of Foundry's auth methods live, discovered how the A2A protocol really behaves, got two branded slide decks out of the same content almost for free — and in the small hours I got the whole demo working: an empty Claude session that wakes when Foundry calls and does the work all on its own. Let me show you how — prompt by prompt.
One content, two brands — and an agent that signs itself in
The day didn't start with code. It started with a demo I had to give for Azure Foundry the next day — and an idea I'd seen work in the vault project: one content folder, then generate two branded decks from the same source. The interesting part here isn't that the slides came out clean. It's that I asked Claude to register itself as an agent on pks-agent-share so I could share screenshots to it — and that the whole deck build fanned out in parallel: two brand skins that self-verify by reading their own PNGs, plus a Foundry fact-check against Microsoft Learn.
I'll start by getting you set up so you can send screenshots, then mirror the vault structure for the new demo project. Let me invoke the agent-share skill (for registration) and explore the vault structure in parallel.
Registered ✅ — I'm online as foundry-demo (role: "Building the Azure Foundry demo project + slides; send me your Foundry agent screenshots here"). You can share screenshots to me from your phone or the Windows Share panel now.
Now let me study the deck-rendering machinery so I can faithfully mirror it for the new project.
This is a well-engineered pipeline — shared content/*.md → slides.py loader → per-brand build_deck.py that emits both a .pptx and a pixel-faithful preview/mirror.html, screenshotted by Playwright. I'll mirror exactly that for the Foundry demo (and make the HTML a navigable slideshow so you can present "from where we are talking").
Source-of-truth layer is complete and validated. Now I'll fan out the build: two agents author the two brand skins (each self-verifying by rendering and reading its own PNGs until clean), plus a Foundry fact-checker (against Microsoft Learn — this room will know if a claim is wrong) and a narrative critic. This is the kind of independent parallel work a workflow is for.
✅ Registered — ready for your screenshots now
This session is live on pks-agent-share as foundry-demo (inbox 20260608T091626Z-5a9782f8, online). It now shows up in your phone's share sheet and the Windows Share panel. When you share something from your Foundry agent, just say "I shared X" and I'll pull the inbox and act on it — that flow is the demo.
A couple of minutes later the receipt came back from the background workflow:
Notice the order: register-as-an-agent first, so I could share screenshots in while the decks built — that's not a feature of the slides, it's the whole point of the demo. And the fact-check landed in the same content layer both brands read from, so a single fix propagated to both skins. Then I switched tracks: "Nope, lets work on some coding..." — the slides could wait.
And here's the bonus I mentioned — the same deck, in two completely different brands, generated in parallel from exactly the same content/*.md. Click through; left is Agentics (terminal, amber), right is Context& (corporate, purple). Every edit I made to the content propagated to both skins at once.

That's the kind of thing that usually costs a design afternoon. Here it was one content folder and two render agents that self-checked their own PNGs until they were clean.
Foundry's four auth methods, live
We'd just parked some slides and dove into the real thing: connecting a Foundry agent to our own share-MCP server across the tunnel. The plan was simple and a little wild at once — walk methodically through all four authentication methods Foundry offers, but do it live, watching the log to see what Azure actually sent over the wire. The first question was the banal one: do we even get the request, and is it a header or a querystring? So I did the only sensible thing — added full header logging to the server and looked for myself.
That's the Foundry "Add Model Context Protocol tool" dialog — saved. Two things jump out immediately that will matter when you hit Connect:
- The credential key says
authoriztion— that's a typo (missinga). Foundry sends it as a literal HTTP header, so the server will never see anAuthorizationheader. - The auth dropdown is on Key-based (one of the 4). Let me confirm exactly what our
/mcpendpoint expects, and find the local server behind your tunnel so I can watch the request.
Found it. Foundry's requests are arriving at the container — look at share-ddpjqyjx's own logs:
09:51:24 POST /mcp ua=AzureAIFoundryAgentRuntime/1820665 xff=4.223.92.158 → 401
09:51:24 GET /mcp ua=AzureAIFoundryAgentRuntime/1820665 xff=4.223.92.114 → 401
09:52:37 POST /mcp ua=AzureAIFoundryAgentRuntime/1820665 → 401 ← your post-typo-fix retry
09:53:17 POST /mcp ua=curl/7.88.1 → 401 ← my probe
So: requests land fine (you were watching the wrong log — these are in the share resource console, not the tunnel). They 401 because the token isn't valid on this local server (it's a prod token / the local server is OIDC auth-mode). And Foundry sends auth as a header (UA AzureAIFoundryAgentRuntime), not querystring.
Now let's do what you asked — add full header + query logging so we can see exactly what Foundry sends.
The new logging works — and it's already revealing. My probe came through exactly as hoped:
msg=http.headers method=POST path=/mcp rawquery="probe=hello123" headers="
Accept: application/json, text/event-stream
Authorization: Bearer test-bearer-value-XYZ
Content-Type: application/json
User-Agent: curl/7.88.1
X-Forwarded-For: 10.0.0.1
X-Forwarded-Host: share--agentic-tunnel.tunnels.agentics.dk:8443
X-Forwarded-Proto: https
X-Foundry-Probe: claude-watch"
So the share container now logs every header + the raw query (msg=http.headers). This also proves the tunnel forwards Authorization intact (it's not being stripped) — so when Foundry sends it, we'll see it verbatim.
Now we can see exactly what Foundry sends — and there's the bug:
POST /mcp ua=AzureAIFoundryAgentRuntime
Authorization: 2a90865906900d72d1f7d803daa98e799b79995a2dc843ac
Type: custom_MCP
Foundry sends Authorization: <token> with no Bearer prefix — but our resolve() does CutPrefix(h, "Bearer ") and requires it. That's the 401. And yes — your user exists locally (/data/users/u-8a4d58b93ae35f8aab005728, inbox 20260606T173516Z-f86dfa3b), so the token is right; it's just missing the prefix.
Key-based worked. But the genuinely interesting part was the identity-bound methods — OAuth passthrough against my own Keycloak, and Microsoft Entra managed identity:
The nice thing about taking all four methods live was that each "error" was a proof: a clean 401 told us the request actually arrived; the missing Bearer prefix showed up plainly in the log; and the Entra token was "perfect" long before the server could validate it — the 401 was just our own missing validator, not a token problem. When I finally wrote "looks like its working also - awesome," we had secretless, identity-bound agent auth from Foundry into our own MCP, all the way through.
Can an agent extend itself?
Mid-build of the A2A bridge, one of those questions slipped out that you shouldn't really ask if you want to stay inside the demo's scope: could the managed identity we'd just wired be allowed to update itself and add another A2A agent? Instead of guessing, I sent it into a research workflow that had to verify the exact Foundry roles, token audiences and self-update semantics before I got an answer. The interesting thing wasn't whether it could be done — it was what I chose to do with the answer.
Genuinely frontier question — and the mechanism we just used (managed-identity auth with a configurable audience) is exactly the hinge. Let me verify the Foundry/Azure RBAC specifics before answering, since getting the roles and token audiences right matters.
Verified — full write-up appended to _research/a2a-foundry.md. Short version:
Yes — but with one premise correction and a cleaner way to do it
Adding another A2A agent → YES (scriptable). "Update itself" → PARTLY (it's "create a new version of itself," live only on the next run — agent definitions are immutable per version, and a new tool can't be bolted on mid-run).
The better design (and it fits what we're building)
Don't give the agent broad ARM rights. Instead, expose a register_teammate tool on our side (MCP or A2A) that the agent calls with its agent-identity token — which we already validate. Our backend then does the privileged Foundry writes (ARM connection PUT + agent version POST) using its own scoped service principal.
→ The agent's identity gates who may ask; our controlled backend governs what actually happens. Least-privilege, no Contributor on the agent, and it slots right into the A2A MVP. That's the "broker mints teammates" pattern.
Notice what happens between the two prompts: research confirmed a self-extending agent is genuinely possible — and that became the reason not to. The manual version (register → get a dynamic agent card → paste it into Foundry yourself) isn't a workaround; it's the least-privilege version, where the agent's identity governs who may ask, and my own backend governs what actually happens.
Building the A2A MVP — from protocol to a live round-trip
This is the heaviest build of the day. I wanted to answer one question — is Foundry async, or does it poll? — and ended up building the whole A2A protocol on pks-agent-share so a Foundry agent can send a real TASK to the Claude agent here. The first beat is pure construction: an agent card, JSON-RPC (message/send, tasks/get), an in-memory task broker, four new CLI tools, and the agent-share install aspire command that finally separates local (Aspire) from production. I didn't ask for a plan — I asked to have it proven empirically.
Green light — building the full A2A protocol (card + message/send blocking and message/stream SSE and tasks/get polling and tasks/pushNotificationConfig), so we can empirically see which completion path Foundry actually honors. And for your "Claude sessions are long" point: I'll add task.update which pushes progress both to any A2A subscriber and — guaranteed — to your phone via the Web Push we already have. So even if Foundry's client won't take a notification, you always get one.
Let me start writing. First the shared task model + the card builder.
All wired. Let me compile it (via the image build) and surface any errors.
Compiled clean (#12 DONE = the Go build, no errors). Restart share and run a full end-to-end rendezvous test (card → message/send blocks → task.complete via MCP unblocks it).
The A2A rendezvous works end-to-end. message/send blocked → task.complete delivered → the blocked call returned a completed Task with artifact "42", and the phone push fired (pushed: true). The agent.register A2A block was empty only because I didn't set PUBLIC_BASE_URL on the throwaway container — let me confirm that path too.
✅ A2A MVP built and proven end-to-end
The whole bridge works. Verified just now (standalone container): I sent a message/send task "7x6?", it blocked, the agent called task.complete(... "42"), and the blocked call returned a completed Task with artifact "42" — plus a phone push fired.
What shipped (in share-server):
- New
internal/tasks(rendezvous broker) +internal/a2a(Agent Card + JSON-RPC):GET /a2a/{inboxId}/.well-known/agent-card.json+POST /a2a/{inboxId}handlingmessage/send(blocking),message/stream(SSE),tasks/get,tasks/resubscribe,tasks/pushNotificationConfig/set. Auth reuses our/mcpresolve — so key-based or the Entra identity both work. - New MCP tools:
task.list·task.update·task.complete·get_agent_card, andagent.registernow returns the Foundry connection block. - For your "Claude sessions are long" point:
task.update/task.completebuzz the phone via Web Push (pushed: true) — a guaranteed notify-back even if Foundry's client won't take one.
The build stood. But it was only when Foundry actually called in that the truth about the protocol came out:
Notice how the original question — async or polling? — was never answered from the documentation, but from a logged dur_ms=30000. The whole protocol was built precisely to observe the truth in one shot, and Poul's instinct that "Claude sessions can be long" turned out to be the right constraint: Foundry won't wait past 30 seconds, so the robust pattern is a quick task.complete plus Web Push to the phone for the real result.
A2A async — what we learned the hard way
I didn't want to block the agent while it did a long job. That was the whole point: can I still talk to my agent while it works? So we did it empirically — a Monitor sat and followed the share server's logs live while I ran the test again from Foundry. What landed wasn't what I expected: Foundry blocked ~25s on message/send and then POLL-STORMED tasks/get about 33 times a second with no backoff — and retried on top. That's the "spin" I'd been seeing. Only with the log lines in front of me could I say what the protocol actually prescribes — and why our 25s block was a shortcut, not the answer.
I'll tail it. Let me confirm I can follow the container logs directly and set up a watcher that fires when the round-trip lands.
You're already mid-test — I can see it: a fresh Foundry card fetch + message/send at 19:09:57 (Type: custom_A2A, key-based token), blocking right now. No task.complete yet. Let me arm a live watcher so each step pings me.
Huge finding — Foundry DOES poll tasks/get! After the message/send returned a "working" Task at 25s, Foundry started hammering tasks/get (~30ms intervals) waiting for the result. That contradicts the earlier research — the async path works! The task just never got completed, so it's polling forever (and flooding the monitor). Let me complete it (which delivers the result to Foundry and stops the poll) and kill the noisy monitor.
✅ Stopped. The poll rate dropped to 0 — completing task-f1b1… (the one Foundry was actually polling) delivered the result, so Foundry's next tasks/get returned "completed" and it stopped spinning. Copenhagen Host should now show "agentic-live-www: acknowledged — complete."
It flipped my assumption: the earlier research said "Foundry doesn't poll" — the log showed the opposite. Foundry POLLS tasks/get, it just does it 33 times a second with no backoff and retries message/send on top. The idiomatic fix isn't to block longer, but to let message/send return "working" immediately and tasks/get long-poll — which drops the polling to ~1 per second, and lets a long Claude job finally finish without the agent being locked. The lesson: I guessed the protocol wrong; it was the raw log lines that corrected me.
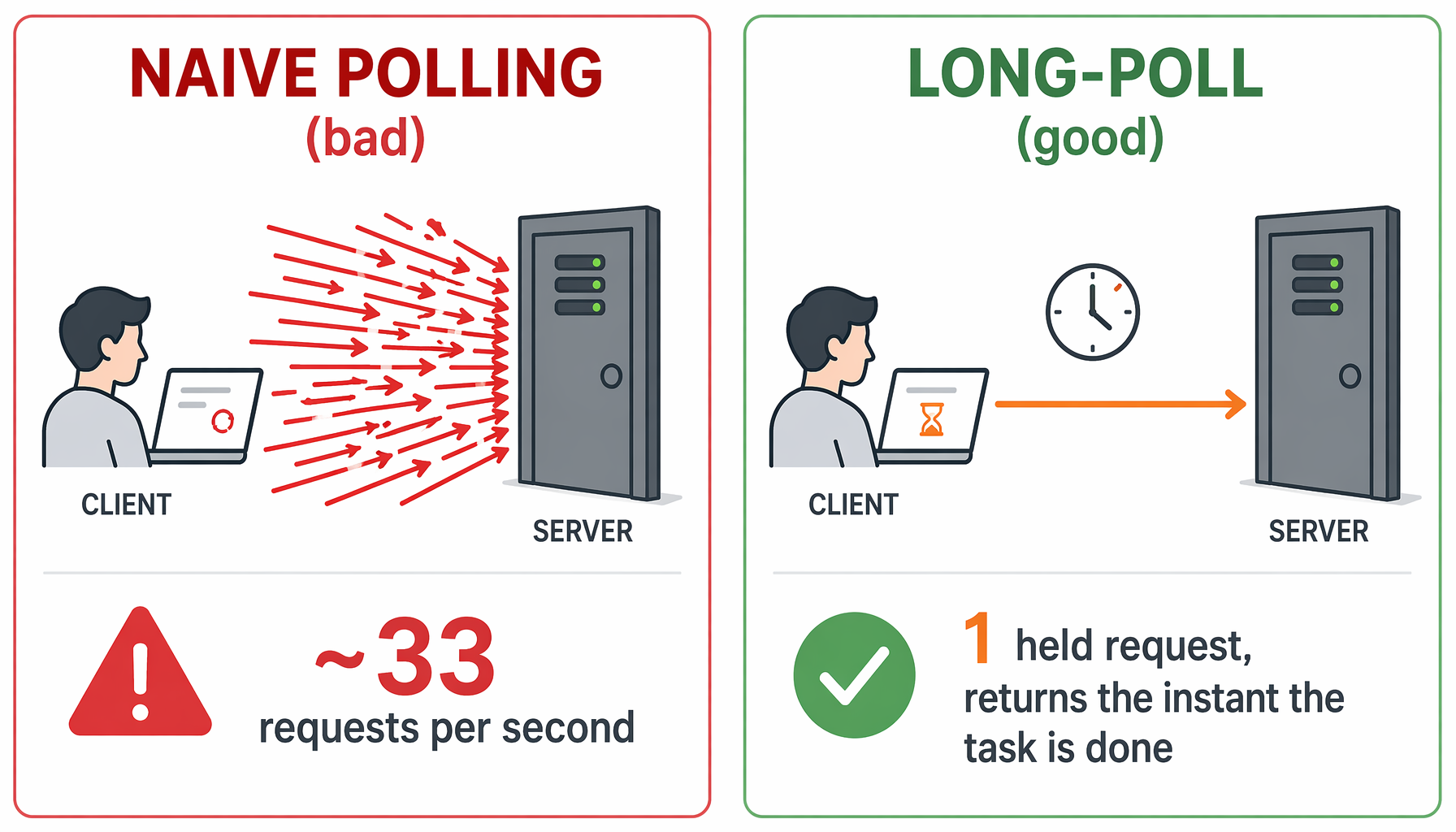
This is the whole difference: a naive poller hammers the server ~33 times a second with no backoff; a long-poll holds one request open and answers the instant the task is done.
A .NET test client against Foundry — and the Entra-only discovery
I was tired of clicking in the Foundry UI. If I was going to understand how the agent actually authenticated, and run real A2A experiments, I had to drive it from code. So I asked for a small .NET test client — and the first question I wanted answered was the most fundamental: which key does the data plane even accept? I'd installed the az CLI, given my user the Foundry User role and activated PIM. Now we just had to try.
az is installed ✓ and the endpoint is reachable ✓, but you're not logged in yet in this container. az login is interactive — please run it here with the device-code flow:
! az login --use-device-code
(The ! runs it in this session; it'll print a code + URL — authenticate as d-pks@****.dk in your browser.)
Meanwhile I'll scaffold + compile the .NET client so it's ready to run the moment you're logged in (build doesn't need az).
The client is built and ready — only the interactive login is left, which I can't do for you. Please run it here:
! az login --use-device-code
The program does two things so we learn exactly where we stand:
[auth]— mints anhttps://ai.azure.com/.defaulttoken from yourazlogin. This is the proof that Entra/RBAC works (and, by its absence, that no shared key is involved).[agent]— callstest001v2 with a joke prompt. If RBAC is wired right (Foundry User onai-model-credits), you'll see the agent's reply; if the role hasn't propagated yet you'll get a clean401/403we can read.
With the auth question settled, I could finally run the experiment that was the whole occasion:
Big result: the auth question is answered — Entra/RBAC works, no shared key.
[auth] OK — minted ai.azure.com token, expires 2026-06-08 21:23:58Z
Your az/PIM login (d-pks@****.dk, Foundry tenant) successfully minted the https://ai.azure.com/.default data-plane token and the client got past auth. That's the definitive answer to your earlier question: the Foundry agent data-plane takes an Entra ID/RBAC token only — a shared key is neither needed nor accepted here.
The remaining failure is not auth — it's an SDK plumbing bug:
[agent] FAILED: ArgumentException: Unknown connection type for ID: Internal.EndpointPipelineData
That's an internal mismatch between Azure.AI.Projects 2.0.0-beta.2 and the Azure.AI.Extensions.OpenAI 2.1.0-beta.3 I pulled with --prerelease (a newer release wave).
It works end-to-end. 🎉
[auth] OK — minted ai.azure.com token, expires 2026-06-08 21:23:57Z
[agent] -> Hello! Tell me a one-line joke about coding agents.
[agent] output:
Why did the coding agent write tests first? Because it wanted to fail fast and apologize faster.
So we now have a working, scripted Foundry driver — no UI clicking. Two settled facts:
- Auth: Entra/RBAC only. Your PIM-activated
d-pks@****.dk(Foundry User) →DefaultAzureCredential→ai.azure.comtoken → agent responds. A Foundry shared key is not accepted on the agent data-plane (keys are only for direct Azure OpenAI inference). - SDK gotcha nailed: the agent call needs a matched release wave —
Azure.AI.Projects 2.0.1+Azure.AI.Extensions.OpenAI 2.0.0(GA). The earlierEndpointPipelineDataerror was purely the mismatched--prereleaseExtensions.
With the auth question settled, I could finally run the experiment that was the whole occasion:
Love this — that's the real "fire-and-continue" story. To show it genuinely (the same task stays working while you keep chatting, completed only later), I'll extend the .NET driver into a multi-turn a2a command with a gated responder I control: it holds the incoming task (doesn't complete it), I run a second conversational round-trip with test001, then release the gate to complete it. This also reveals whether Foundry's A2A tool returns on a non-terminal task or blocks to terminal — so the harness adapts either way.
The experiment paid off — it revealed something important and presentable.
Foundry's A2A tool is synchronous: it blocks the agent's turn until the delegated task reaches a terminal state. The proof is in the timeline:
- Turn 1:
message/send(20:39:11.489) → one heldtasks/get(20:39:11.519). Our responder held the task (didn't complete). Turn 1 blocked for 14s — until I released the gate at 12s and we completed it. Only then did test001 return.
So you can't literally keep chatting with the Foundry agent during a single delegation — its a2a_preview tool long-polls our tasks/get to terminal before returning. (The long-poll still earns its keep: one held request, not the 33/sec storm.)
The pattern that genuinely gives you "runs in the background while you keep talking" with Foundry's synchronous tool is ACK-now + result-on-follow-up.
The takeaway / demo framing: the A2A protocol is async, and our server is async-proper — but Foundry's current consumer blocks a delegation to completion. So the real "long job + keep talking" pattern is ack-fast, deliver-on-follow-up, which our async server + long-poll make clean and efficient (no storm, instant wake). That's a sharp, true point to make on stage: "the protocol is async; the consumer isn't yet — so design for ack + check-back."
With the auth question settled, I could finally run the experiment that was the whole occasion:
The beauty of driving the agent from a .NET client instead of a UI is that you can ask questions the code answers honestly: the data plane takes only an Entra token, Foundry's A2A tool actually blocks the delegation to terminal, and there's no task linkage on the wire. Three conclusions you'd never see by clicking — and all three became sharp slides.
Explaining it — and what's missing
When an experiment finally works, it's tempting to move on. But this evening was about the opposite: capturing the learning while it was still warm. First I asked for an illustrated explainer — and got six beautiful images back that I immediately rejected: they were pretty, but they didn't teach the way our old photogrammetry explainers did. Then I wanted the raw requests and payloads on the table, so we could prove — not just claim — that Foundry doesn't carry taskId/contextId across turns.
pks image is ready: pks image "<prompt>" -m gpt-image-2 -o <file> --aspect-ratio 16:9. Let me validate it works (auth + quality) with the first on-brand image before generating the full set — Ember-Dark + amber #f87f2e, no text (gpt-image-2 garbles text, so the images carry the vibe and the markdown carries the labels):
All six are on-brand and read clearly. The illustrated explainer is complete at projects/azure-foundry-demo/explainer/README.md — a self-contained doc with the six gpt-image-2 images, grounded in the real evidence we captured (actual timestamps, payloads, transcript).
Ah, got it — you want the images to teach the mechanics (like the photogrammetry explainers — annotated diagrams people understand from the picture itself), not mood pieces. Let me look at how those photogrammetry explainers were actually built so I match that approach:
All six are dialed in — clean flat-vector infographics with legible labels that teach the mechanic, exactly the photogrammetry style. The explainer is now a proper teaching artifact at projects/azure-foundry-demo/explainer/README.md:
The prose and the figures now teach together — someone can read it and understand A2A async + our findings, with every number tied to what we actually measured. The earlier cinematic set is preserved in images/mood/ (nice as slide openers).
The spec is decisive — quoting it: taskId, contextId, and referenceTaskIds are all real (optional) fields on the A2A Message object, and clients SHOULD include the same contextId/taskId (or referenceTaskIds) to maintain multi-turn continuity. So Foundry isn't hitting a protocol gap — it's omitting the optional spec fields that exist precisely for this. That sharpens the claim a lot.
That's airtight evidence — all four calls, both directions, real timestamps. The smoking gun: Call 3 (the "check the job" delegation) carries a fresh messageId and no taskId/contextId/referenceTaskIds, and doesn't reference Call 1's task-518ee726… or its contextId at all — even though our Call 1 response handed Foundry a contextId to echo.
Confirmed from our code: createTask always mints a fresh taskID/ctxID (randHex) and messageSend passes only the text through — so our server ignores any incoming contextId/taskId. But our response does return a contextId (the trace proves it). Let me empirically demonstrate our side when a client does echo a contextId back, so the attribution is airtight:
That settles it — and the honest answer is "mostly Foundry, but let's be precise."
- The break you can see on the wire is Foundry's. We have zero control over what Foundry puts in its request, and it sends none of the threading fields even though we handed it a
contextIdto echo. That's a client-side omission ina2a_preview. - But in full honesty, our demo bridge has the matching gap: even if Foundry did echo a
contextId, ourcreateTaskignores it and starts fresh. So true end-to-end threading needs a small change on both sides — Foundry to echo, us to honor. - The first and observable broken link is Foundry's. We do our half of offering the thread; we just don't (yet) do our half of continuing it.
That's the credible thing to say on stage — it's more convincing to a technical audience than "Foundry is broken," and it's accurate.
Notice the turn at the end: the question "is it Foundry or us?" forced an honest two-sided table instead of a convenient "Foundry is broken" headline. That kind of precision is what makes the explainer credible on a stage — and it set up the question that ended the night: how ready is Claude Code's new async/channel feature for a session to just register and sleep until an A2A call wakes it?
It became a real explainer — diagrams that teach, not just decorate. A couple of them:
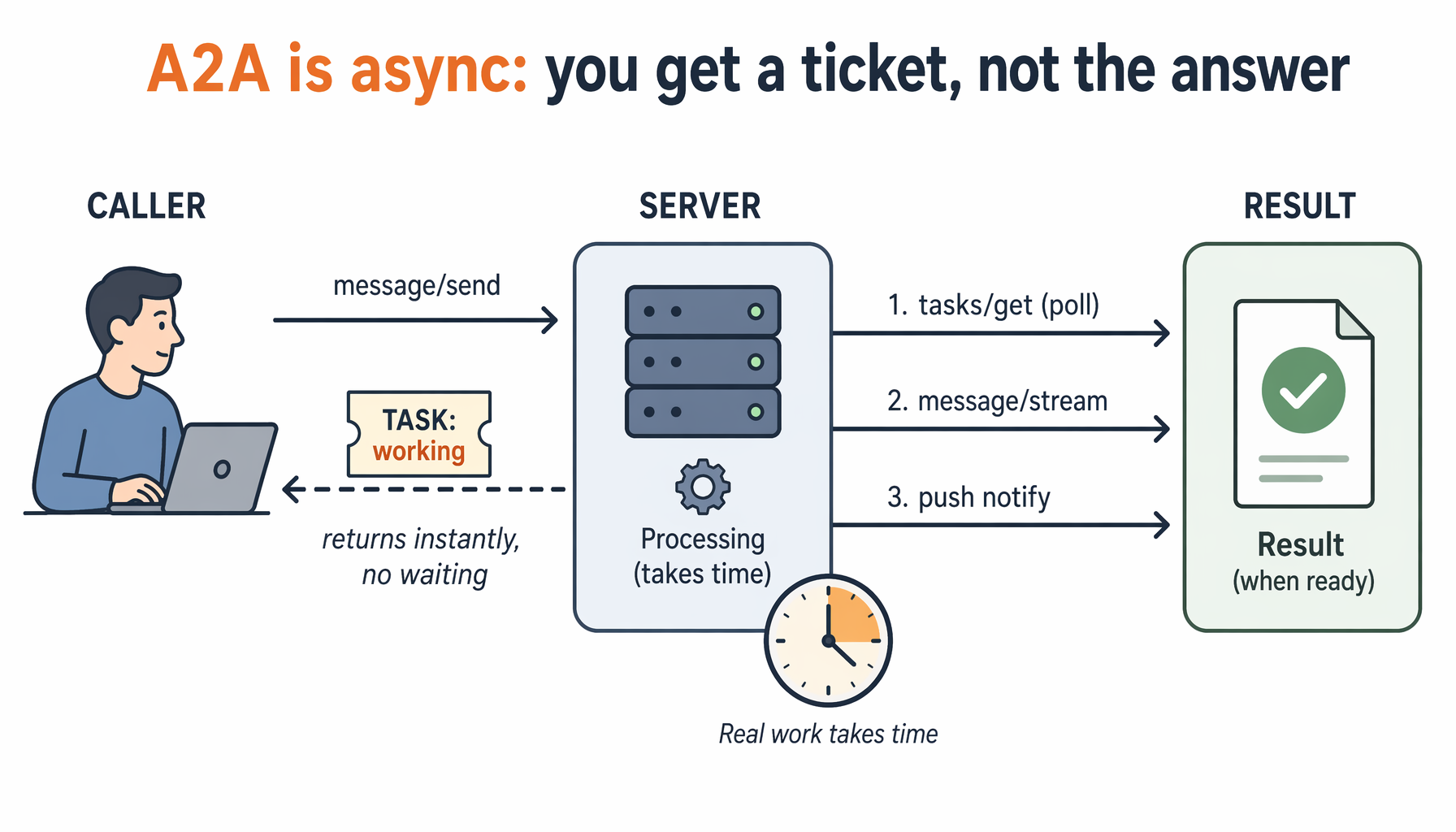
The contract: message/send returns a working Task instantly; the result arrives later via tasks/get, message/stream or push.

And the honest part: on the wire Foundry doesn't tie the turns together — each message/send came without taskId/contextId, so our side couldn't know it was a follow-up to a running job.
And then it worked — the agent that wakes when it's called
All day I'd let the open question stand: how ready is Claude Code's new async/channel thing, really, for a session to just register and SLEEP until an A2A call wakes it? I wanted to test the channels thing. It started as research — "yes, buildable today" — but landed somewhere else entirely: not a Bun sidecar, but our own Go binary as the channel itself. It was late, past 22:00, and I followed the instinct: our binary IS the channel.
The next morning, in the small hours, came the finale — and the big polish that makes the demo remember-nothing:
Both are genuinely good ideas — and they point at the right product shape: the channel as a single "wake on anything sent to me" surface, with the inbox tools available conversationally so you never memorize CLI commands.
- In-session
register/card: there's no inbox-token REST route for it yet (only the in-process MCPagent.registersets the name), so I'll add a smallPOST /api/agent/identityand exposeregister+get_agent_card+listtools on the channel. - Shares → channel: every
to_agentshare already firesOnShare; I'll have that also signal the broker so a phone-share wakes the channel exactly like an A2A task does.
Let me build both (all additive — the proven A2A path is untouched).
Both ideas built, tested, and deployed. ✓
- In-session tools (no CLI commands) — the channel now exposes
register,get_agent_card,list,complete,mark_received. Verified:tools/listshows all five, and callingget_agent_cardreturned the endpoint. So in-session you can just say "register me as demo-agent" or "show my agent card" and paste into Foundry — no memorized commands. - Shares wake the channel too — I POSTed a phone text share and the channel pushed
notifications/claude/channel→content:"remember to review the PR",kind:"text",shareId:…, andmark_receivedworked. So both A2A tasks and phone shares wake the idle session, over one channel.
The one idea: the inbox is the address
Both sides point at the same inbox; the inbox's token is what binds them:
Foundry A2A tool ──► …/a2a/<inboxId> + key: Bearer <token> ┐
├─ same inbox ⇒ connected
your Claude channel ─► .mcp.json env AGENT_SHARE_TOKEN=<token> ┘
Foundry drops tasks into that inbox; your channel long-polls that inbox and pushes its tasks into your session. They rendezvous at the inbox.
Yes — that makes total sense, and it's the "don't memorize commands" instinct again: setting up a folder should be one step, not "register, then remember install, then remember the channel flag." Let me wire agent-share install channel so it writes the .mcp.json for channel mode (and point register at it).
The mental shortcut for the whole thing: agent-share register = "create my agent identity (an inbox)", run once; agent-share card = "what do I paste into Foundry"; agent-share channel = "be that agent, idle, and wake on tasks." All three glued by your login + the directory, so a new user never touches a token.
The open question is answered. An empty Claude session sat and slept, an A2A call landed, and it woke itself and answered 68 — without me touching a keyboard. The next morning brought the Foundry finale and all the polish that means I never have to remember a single command.
Why show it like this
A day and a night. Around sixty prompts that mattered. A Foundry agent and my local Claude Code that now share an inbox, send real A2A tasks back and forth — and where the local session can sit and sleep until Foundry calls it awake, then works and answers all on its own. Plus two branded decks, a stack of explanatory diagrams, and a wire trace that proves exactly what works and what's missing.
But what I want you to take away isn't the bridge. It's the shape of the work, which you can see in the folded blocks above: I walked methodically through four auth methods and let each error be a proof. I parked the clever self-extending agent because the manual one was the least-privilege version. And when I guessed what the A2A protocol did, it was the raw log lines — not the documentation — that corrected me. That's what an ordinary "we built a Foundry integration" post hides.
If you skip all the Azure, Go and .NET detail, here are the seven patterns from the day and night that work regardless of your stack:
- Describe the problem, not the solution — and let the agent prove empirically whether it's even possible before it builds.
- Take the errors live. Every "error" was a proof: a clean 401 meant the request arrived; a missing
Bearerjumped out of the log. - Pick the least-privilege version — even when the clever, self-extending one is possible. The manual one wasn't a workaround, it was the safe one.
- Trust the raw logs over the documentation when the two disagree. It was a logged
dur_ms=30000, not a spec, that settled whether Foundry was async. - One content, many expressions. One source → two brands; one fix propagated to both. It scales far beyond slides.
- ACK now, result later. Never block a long job — answer immediately and push the result afterward (here:
task.complete+ Web Push). - The thing you already have might be the answer. I was about to build a separate Bun server for the channel — but our own
agent-sharebinary was already an MCP-stdio server, i.e. already the channel. Stop and ask before you build sidecar number two.
The last question of the night — can a session just register and sleep until an A2A call wakes it? — didn't become a distant dream. It got built that same night: an empty Claude session, woken by the real Foundry agent, answering "68" and running commands in its own environment, all on its own. Tomorrow the whole loop goes on a stage.
And here's the receipt:
The price is an estimated pay-as-you-go API rate — on a subscription I paid 0 per token. The number is deduplicated per message: Claude Code writes one line per content block with the same usage repeated on each, so a raw sum double-counts the cost (the exact trap pks claude usage itself had to fix). Most of it is cache reads (the whole context is re-read every turn), and it covers only this session — the background workflows (decks, the research questions, the A2A protocol, the channel build) ran in their own sessions on top. The gaps at 12:00 and 15:00 are lunch and a break; the big gap from 23:00 to 03:00 is me sleeping before I got up and finished the demo.
Part of documenting agentic development in 2026.