Tidligere version (v1) (2026-05-27, "Node/edge + jeg-stemme")
Dette er en arkiveret tidligere udgave af denne post. Den aktuelle version kan være ændret. Læs den aktuelle version →
Erstattet `knude`/`kant` (akademisk graf-teori-calque) med `node`/`edge` overalt — calques.txt-driven cleanup. Tilføjet jeg-stemme i definitions-sektioner (deterministisk-vs-AI, hvorfor-en-DAG-og-ikke-tabel) som åbnede med termer i stedet for iagttagelser. Reverse-lookup-sætning normaliseret fra maskinoversat-shape til naturlig dansk-mix prosa.
Grafen var der hele tiden
Pks brain ingest producerede ikke en log. Den producerede en graf. Fire nodes, tre edges, og en join-akse jeg ikke kunne se før product-cli viste mig hvordan en typed DAG ser ud andre steder. Det 3. indlæg om hvordan AI-hjernen er bygget op under motorhjelmen.
Da jeg startede pks brain 14. maj havde jeg ikke en graf i hovedet. Jeg havde fire JSONL-filer. Det tog mig et par uger at se at det var det samme.
Det her er det 3. indlæg i serien om pks brain. I det første gennemgik jeg hvorfor AI-hjernen eksisterer; i det andet viste jeg hvad den producerer. Jeg opdagede et par uger inde at pipelinen var en graf — bare uden at jeg havde kaldt det det. Det her indlæg er hvad jeg så, da jeg endelig fik øjnene op.
Erkendelsen kom fra dig
Det her indlæg er skrevet under en session hvor du (læseren — Poul, som du jo selv er hvis du læser det her i din egen blog) skar ind med følgende prompt:
Det var den prompt der tvang den her artikel ud i lyset. Indtil da troede jeg vi byggede én ting: "en background-agent der cruncher sessions". Den prompt opdelte det i to: ingest-laget (deterministisk firehose-dump) og graf-laget (sammenkædning af entiteterne). Det andet eksisterede allerede — som biprodukt af det første. Jeg så det bare ikke.
Fire nodes, tre edges
DAG'en pks brain producerer består af præcis fire node-typer:
- Session — én Claude Code-session, identificeret ved UUID. Lever som en JSONL-fil i
~/.claude/projects/<projekt>/<uuid>.jsonl. - Prompt — én brugerprompt inde i en session. Tekst, timestamp, eventuel slash-command.
- ToolCall — én tool-invokation drevet af en prompt. Værktøjsnavn, varighed, fejl-flag, parent assistant-uuid.
- File — én fil rørt af en ToolCall. Filsti, op (
read/write/edit/multi-edit), success-flag.
Mellem dem er der tre edges — alle peger samme vej:
Session ──contains──→ PromptPrompt ──drove──→ ToolCallToolCall ──wrote/edited/read──→ File
Visuelt er det den her struktur fra det første indlæg — værd at have foran sig:
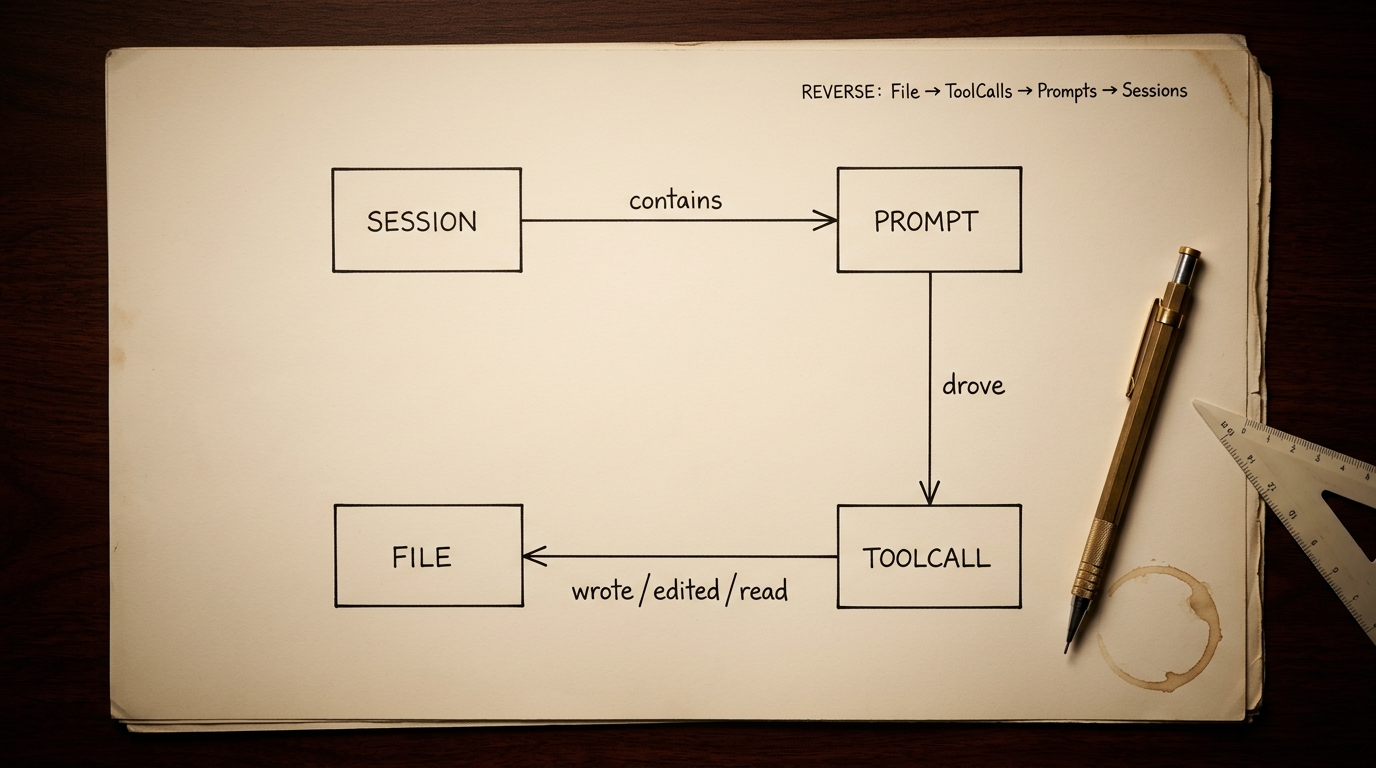
Det er en DAG — alle edges peger nedad, ingen cykler. Det er det der gør queries forudsigelige; jeg behøver aldrig at frygte at en File-lookup ender tilbage ved sig selv.
Firehose-rækker er edges forklædt som tabelrækker
Ingest-fasen producerer fire JSONL-filer i ~/.pks-cli/brain/. Hver række ligner en database-tabelrække. Men hver række er også implicit en edge i grafen:
prompts.jsonl — én række pr. brugerprompt. Repræsenterer både Prompt-noden og dens in-edge til Session:
{
"sessionId": "1a475348-b3f7-4038-8256-2f364859c3d2",
"projectSlug": "-workspaces-agentic-live-www--...",
"timestampUtc": "2026-04-06T15:28:44.458Z",
"promptId": "0c2762b1-7e6f-45bd-8372-7b499b8a6edd",
"uuid": "85993c63-296b-4d22-a029-9ddacb9a9db5",
"text": "Project: pks-agent-inbox\nan email inbox for agents\n\nScope: scarfold\n\n...",
"textHash": "d39524e8cbdf3c4c",
"cwd": "/workspaces/agentic-live-www/.agentics/_work/...",
"gitBranch": "task/mnmzxlux-85f5wh",
"length": 1901,
"isSlash": false
}
tools.jsonl — én række pr. tool-invokation. Repræsenterer ToolCall-noden plus from-edgen til Prompt (via parentAssistantUuid):
{
"sessionId": "agent-a6e61f715b03161e3",
"projectSlug": "-tmp-pks-runner-jobs-...",
"timestampUtc": "2026-04-12T15:40:17.614Z",
"toolName": "Glob",
"toolUseId": "toolu_014X92w1RkizWovUjbToPuTf",
"inputDigest": "f7361c8f7acae6c4",
"inputPreview": "{\"pattern\":\"/tmp/pks-runner-jobs/.../**/*\"}",
"parentAssistantUuid": "c0c06cbd-5884-4885-85bb-5d27f47348f0",
"durationMs": 16,
"isError": false,
"resultSize": 1217,
"isMcp": false,
"isSubagent": false
}
files.jsonl — én række pr. fil-operation. Repræsenterer både File-noden og wrote/edited/read-edgen fra ToolCall:
{
"sessionId": "agent-a6e61f715b03161e3",
"projectSlug": "-tmp-pks-runner-jobs-...",
"timestampUtc": "2026-04-12T15:45:18.075Z",
"op": "write",
"filePath": "/tmp/pks-runner-jobs/.../design-system/components.md",
"success": true
}
errors.jsonl — fejl-events tilknyttet ToolCall-nodes. Ikke en separat node-type, mere et attribute-set for ToolCalls der gik galt.
Joinet er gratis fordi der er en timestamp
Det interessante er at de fire firehoses ikke har explicitte foreign keys mellem sig. De har bare (sessionId, timestampUtc) i fælles. Det gør reverse-lookup'en — givet en fil, find prompten der drev skrivningen — triviel: filter files.jsonl på filePath, og for hver matched række filter prompts.jsonl på (sessionId, timestampUtc ≤ fileTs) og tag den seneste prompt før edit'en.
Det er præcis hvad pks brain commit-plan kører i det 4. indlæg — uden at instantiere graf-objekter, uden at bygge et adjacency-array. Bare en JSONL-stream og en binary search.
Deterministisk vs. AI-syntetiseret
Ingest kører på 1–2 sekunder fordi der ikke er en model i loopet. Den læser session-JSONL-filer, ekstraherer felter, skriver rækker — 100% deterministisk. Det er bevidst: jeg vil kunne genberegne hele firehose'en uden at det koster en token.
Oven på den deterministiske graf ligger to AI-lag:
- extract — pr. session genererer modellen et markdown-resumé baseret på prompts.jsonl + tools.jsonl + files.jsonl filtreret til den ene session. Output landes som
.pks/brain/extracts/<sessionId>.md. - synth + wiki — klyngedanner sessions efter tema (gennem extract-tekster + filsti-mønstre + tool-historik) og syntetiserer pr. klynge til en wiki-side. Output landes som
.pks/brain/wiki/<tema>.md.
Grunden til at jeg holder dem adskilt: den deterministiske del kan jeg genkøre gratis så ofte jeg vil. AI-laget koster tokens, og det er fortolkning — ikke sandhed. Hvis brain-extract-skillet ændres, kan jeg re-køre extracts uden at røre ingest. Og hvis ingest er ødelagt, kan jeg se det med det samme i stedet for at opdage det via en wiki der lyver troværdigt.
Hvorfor det er en DAG og ikke "bare" en tabel
Jeg overvejede faktisk at slå alle fire firehoses sammen til én bredtabel: (session_id, prompt_id, tool_call_id, file_path, timestamp). Det ville fungere for de fleste queries.
Men brain er ikke kun nuværende-tilstand. Den er et tids-stempel per edge, og edges ankommer skævt — en prompt skriver én fil først, så endnu en, så et tool-call der intet skriver, så endnu en fil-edit. At behandle den som en flat tabel ville smadre sekvensen mellem events — hvilken prompt udløste hvilken specifik fil-edit. DAG-modellen siger eksplicit: edgen ToolCall → File har et timestamp tæt på ToolCall, og edgen Prompt → ToolCall har et timestamp på Prompt. Det er sekvensen der gør commit-plan-queryen i næste indlæg mulig.
Næste indlæg
Det 4. indlæg viser hvordan det her bliver til brugbar output: tag staged filer, kør grafens reverse query, få commit-messages der ved hvorfor. Plus en lille øvelse i hvor meget hurtigere det blev da grafen erstattede skanneren.