Tidligere version (v1) (2026-05-27, "Tabel + CommitBlock + artifact")
Dette er en arkiveret tidligere udgave af denne post. Den aktuelle version kan være ændret. Læs den aktuelle version →
Erstattet benchmark-pseudo-terminalen med en markdown-tabel (alignment-decoration, ikke real terminal-output). Indført ny `<CommitBlock>`-komponent som rendrer commit-hash + body som ét semantisk kort i stedet for to separate kodeblokke. Tilføjet artifact-side for /commit-message-skillet med fil-tree + inline SKILL.md.
Fra ændrede filer til commit messages
Pks brain commit-plan kører grafens reverse query: tag staged filer, find de prompts der drev hver ændring, returnér grupperet plan. Det 4. og sidste indlæg i serien viser hvordan det blev til en /commit-message-skill — og hvorfor den var ubrugelig før vi flyttede planneren fra rå-JSONL-skanner til firehose-direct-read.
Jeg startede den her session med at lede efter en gammel samtale jeg havde glemt indholdet af. Du (jeg, læseren) skrev:
AI-hjernen fandt den. Tre dage gammel session, fuld af notater om hvordan man linker filer til de sessioner og prompts der havde rørt dem. Og så blev spørgsmålet umiddelbart: kan vi gøre det her til en faktisk skill?
Det er det her indlæg handler om. Det 4. og sidste indlæg i serien om pks brain (efter hvorfor AI-hjernen eksisterer, hvad den producerer og hvordan grafen er bygget op).
Hvad skillen gør
/commit-message er en Claude Code-skill der kører hver gang man har stagede filer og vil skrive en ordentlig commit-message. Flowet er:
git diff --cached --name-only→ den nuværende staged-listepks brain commit-plan --files-from <list> --include-prompts --format json→ grafens reverse querygit diff --cached→ den faktiske diff (hvad-er-ændret)- Synthese: subject = hvad (ét konkret user-visible change), body = hvorfor (synthesised fra prompts der drev edits)
- Output i Conventional Commits-format, så
semantic-releaseog lignende kan rulle dem sammen til release notes senere
Pointen er at AI-hjernen kender konteksten bag hver fil-ændring — ikke kun selve ændringen. Når man skriver feat(blog): publish coolify-destinations-pr post er det fordi grafen kunne pege på de prompts der oprindeligt diskuterede coolify-destinations-PR'en — ikke fordi modellen gættede en god overskrift ud fra filnavnene.
Grafens reverse query
Det 3. indlæg etablerede at grafen er en DAG med fire knuder: Session → Prompt → ToolCall → File. Forward er trivielt. Reverse er det interessante:
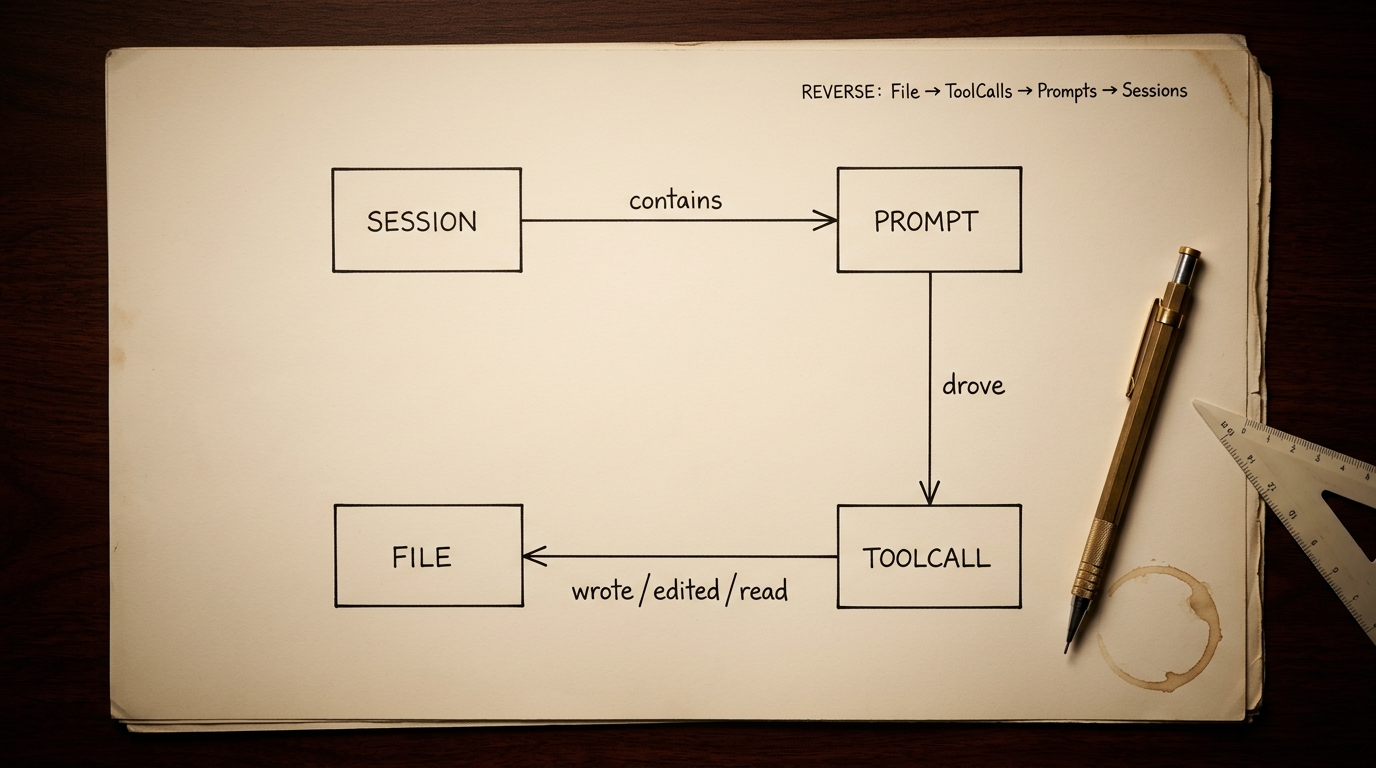
pks brain commit-plan kører præcis det reverse-query: for hver staged fil, find ToolCalls i files.jsonl der har skrevet til den filsti; for hver matched ToolCall, find den seneste brugerprompt i prompts.jsonl med samme sessionId og timestampUtc ≤ tool-call.ts; gruppér efter primary-session og returnér.
Resultatet er en JSON med:
groups[]— filer der hænger sammen (samme primary session)groups[i].prompts[]— de brugerprompts der drev edits til de filer (verbatim tekst, timestamp)groups[i].contributing_sessions[]— andre sessioner der også rørte filerne
Skillet bruger den output til at vælge en type (feat/fix/chore/docs), et scope (det mest specifikke område), og et subject der reflekterer det mest user-visible change — så syntetiserer body'en fra prompt-teksterne uden at citere dem ordret.
Hvad gjorde den ubrugelig først
Da skillet blev skrevet, var pks brain commit-plan implementeret oven på en per-fil scanner der re-parsede rå ~/.claude/projects/**/*.jsonl fra bunden af hver gang. For 52 staged filer tog det ~200 sekunder. Tre minutter. Det er ubrugeligt for et "tryk-her-så-commit"-flow.
Du skar ind:
Det opdelte arbejdet i to features (præcis som indlæg 3 beskriver): ingest-laget — som allerede producerede en graf i form af firehoses — og graf-laget, der bare skulle læse den eksisterende graf i stedet for at re-parse rå-data.
Fix'en var en ~80-linjers omskrivning af BrainCommitPlanner i pks-cli. Strøm én pass over files.jsonl filtreret til input-filerne, lav en binary-search-join mod prompts.jsonl for prompts før hver edit-timestamp. Hold scanneren som fallback for når firehose'en mangler. Tilføj en auto-ingest før query så grafen er frisk.
Resultatet på den samme 52-filers staged-set:
| Implementering | Tid |
|---|---|
| Firehose grep (rå lookup over indekseret firehose) | ~10 ms |
pks brain commit-plan (ny — auto-ingest + firehose-read) | ~1,3 s |
pks brain commit-plan (gammel — per-fil scanner) | ~200 s |
Speedup: ~165×. Det forvandlede skillet fra "for langsom til at bruge" til "kør den hver gang".
Dogfood-momentet
Den her serie er skrevet i den session hvor skiftet skete. Den her commit blev skrevet af /commit-message selv — skillet brugte den nye firehose-implementering til at finde de prompts der drev sin egen rewrite, gennem en JSON-output på 1,3 sekunder, og syntetiserede:
feat(brain): wire commit-planner to firehose graph
The graph itself already existed — pks brain ingest materialises
files.jsonl as the File↔Session edge table — but BrainCommitPlanner
ignored it and re-parsed every raw ~/.claude/projects/**/*.jsonl per
input file, taking ~3 minutes for a 52-file plan. The planner now reads
the firehose directly with a binary-search join on prompts.jsonl and
keeps the scanner as fallback when the firehose is absent.
Hele kæden — ingest, firehose, graf-query, skill, conventional commit — lukkede loopen på sig selv. Se artifact-siden for /commit-message hvis du vil læse selve skillen.
Hvad får man konkret ud af det
Tre konkrete ting:
- Bedre commit-messages. Subject = ét user-visible change. Body = hvorfor, ikke hvad. Hvad → diff. Hvorfor → kun synlig hvis nogen har et signal fra prompts der drev edits. Det signal fandtes ikke før grafen.
- Bedre release notes. En release-pipeline (semantic-release / conventional-changelog) tager subject-listen og bygger "## Features" / "## Bug Fixes" automatisk. Body'erne overlever som expandable detail. Pludselig er release notes ikke et review-step men en bivirkning.
- Sporbarhed. Hvert commit kan slås tilbage til præcis de prompts der diskuterede det. Det er ikke et "AI wrote this" disclaimer — det er at kunne læse hvad der blev sagt før koden blev til.
Slut på serien
Det her var det 4. og sidste indlæg i serien om pks brain. Genopfrisk de tre andre hvis du sprang ind midtvejs:
- Hjernen bag — hvorfor AI-hjernen overhovedet eksisterer
- En wiki skrevet af vores AI-hjerne — hvad den producerer
- Grafen var der hele tiden — hvordan den er bygget op
Næste skridt for mig: en visualisering der renderer din egen pks-brain-graf som en interaktiv DAG-visualisering. Hvis bonusset rammer, lander det som indlæg 5. Hvis det ikke gør, lukker serien her — fire indlæg, ét repo, ~7.000 prompts kondenseret til en DAG der ved hvorfor mine filer eksisterer.