The brain behind
7,000 prompts, 88,000 tool calls, 46,000 file ops — all sitting in ~/.claude/projects/ and never read again. Pks brain is the quiet crunching that turns vibe-coded chaos into ADRs, feature specs, and searchable wikis. It started as one evening in May and became a DAG.
I have 7,000 prompts, 88,000 tool calls, and 46,000 file ops sitting in ~/.claude/projects/ right now. I'm never going to read any of them again. That annoyed me enough that I built a brain to do it for me.
It didn't start as a product. It started as a sentence I wrote down on May 14th because I was tired of forgetting my own projects — and because Andrej Karpathy had just posted about his own "second brain" concept and I wanted to build something in that direction, based on what I already had lying around: my Claude Code sessions.
(The prompt is verbatim — half Danish, half English, the way it was actually typed. Translation would have stripped the texture that made it land.)
That was it. No API. No schema. No graph. Just an idea that the way I actually work — vibe-coded, half-finished, ten projects open at once — could be the input to a process that quietly distilled it into the kind of artefacts real projects have: ADRs, feature specs, a wiki, a bad-habits report about myself.
Start vibe, go pro
Anyone who has vibed their way through six months of AI-assisted development already knows: you start WAY too many things. Most die. The few that survive grow from "one evening's nonsense" into "I use this every day" without any formal moment where you decided that's what it would be.
The problem isn't that you lack documentation. The problem is that you've written it — across Claude sessions, in commit messages, in half-edited markdown files — without it ever consolidating. It sits in ~/.claude/projects/ as JSONL from every session, every prompt and every tool call, but in a form nobody is going to read again.
Pks brain is the attempt to harvest that documentation without making you behave like you're working on a "real" project. You vibe. The brain crunches in the background. When I open a project again three weeks later there's actually something I can read — without me having to write it.
What pks brain became
The original idea settled into five phases, each with its own command and its own checkpoint so any phase can be re-run independently:
pks brain ingest— deterministic dump of every session JSONL into compact firehoses (prompts.jsonl,tools.jsonl,files.jsonl,errors.jsonl)pks brain extract— AI-generated markdown summary per session, driven by an editablebrain-extractskillpks brain synth— clustering: thematic groups across sessionspks brain wiki— per-cluster wiki pages generated from the synthesispks brain adr— architectural clusters distilled into ADRs
The phase split is deliberate. Deterministic ingest is cheap and runs in 1–2 seconds; the AI-driven phases cost tokens and run only when you ask. pks brain refresh chains them for a full pass; the rest of the time you just re-run the one phase you need.
Output lives in two places:
- The user-scoped cross-project firehose under
~/.pks-cli/brain/— every session across every project as one long stream of rows. The shared engine room. - Project-local synthesis artefacts under
./.pks/brain/inside each git repo — the wiki, the ADRs, the feature specs for this project. The public room where synthesis lands.
In this repo right now I have around 7,000 prompts, 88,000 tool calls, and 46,000 file ops in the firehose, against 2,940 AI-generated session extracts. Half a year of vibe-work, ready to be read by a model that isn't me.
The pivot: it turned out to be a DAG
I didn't know that on May 14th. It only became clear here at the end of May — after a week working with product-cli, which uses a typed DAG (Feature, ADR, TC, source files) to bind architecture together — that the brain had already been producing something nearly identical. Just without me calling it a graph.
Every row in files.jsonl is an edge: (session_id, tool_name, file_path, timestamp). Every row in prompts.jsonl is a node — the user prompt that drove the edges that followed. Use timestamps as the join axis between the two firehoses and you have a File↔Session DAG with Prompt attribution. For free. Pre-computed. Ready to query.
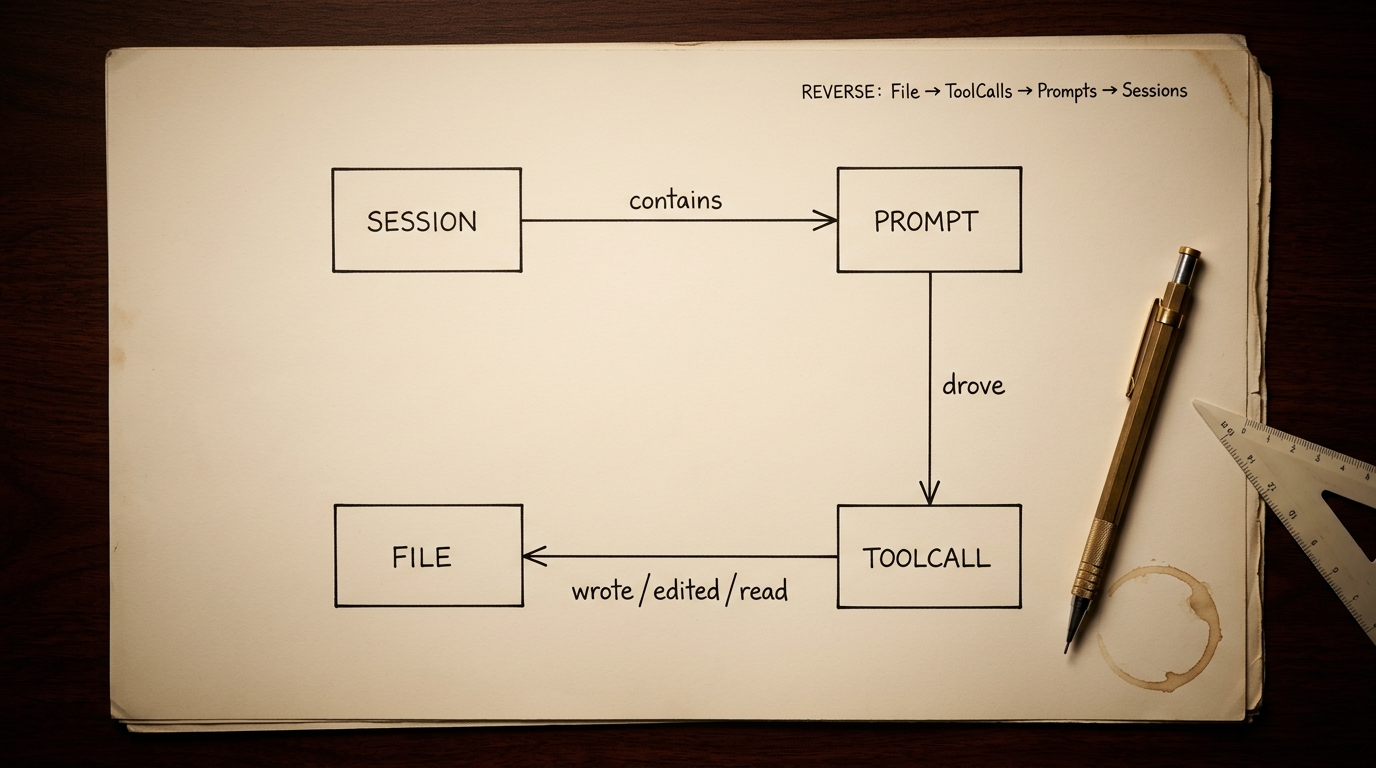
Forward is trivial — a Session contains a series of Prompts, each Prompt drives a number of ToolCalls, each ToolCall writes/edits/reads a file. The interesting direction is the reverse: I have a file, and I want to know what happened to it. The reverse query — File → ToolCalls → Prompts → Sessions — is exactly what pks brain commit-plan runs every time it has to explain a commit. Take the staged files, look them up in files.jsonl, find the prompts that drove the changes, return the grouped plan. It tells the commit-message writer why the changes happened — not just what changed.
The 4th post is about exactly that flip: how we took the graph layer — which had been there all along, built by ingest in two seconds — and used it to write commit messages that know why. When we moved pks brain commit-plan from re-scanning raw JSONL per file to reading the firehose directly, the skill suddenly became fast enough to run on every commit. This whole series was triggered by that flip.
The four posts
- The brain behind — this post. Why the brain exists, what it consists of, and how the DAG emerged.
- A wiki written by our AI brain — a tour of the wiki output. What do the auto-generated pages look like, and how accurate are they when you set a wiki page next to the source code it was synthesised from?
- The graph was there all along — the architecture in detail. Which nodes exist (Session, Prompt, ToolCall, File), which edges connect them, what's stored deterministically versus AI-generated.
- From changed files to commit messages — how we join staged files against the graph to find the prompts that drove each change, and how we use them to write
feat(blog): publish coolify-destinations-pr post-level commit messages automatically. Including why this only became usable when the graph replaced the scanner.
Who this is for
If you:
- use Claude Code actively and your
~/.claude/projects/directory keeps growing - wish you got something back from that work — beyond the code that's already in git
- have tried to "write ADRs after the fact" and discovered it never happens
… then this is for you. The brain isn't doing anything magical. It harvests what you've already produced, makes it searchable, and comes back once a day asking whether anything new happened.
What's sitting in your own ~/.claude/projects/ that you're never going to read again?
Posts in this series
- 01The brain behind7,000 prompts, 88,000 tool calls, 46,000 file ops — all sitting in ~/.claude/projects/ and never read again. Pks brain is the quiet crunching that turns vibe-coded chaos into ADRs, feature specs, and searchable wikis. It started as one evening in May and became a DAG.
- 02A wiki written by our AI brain103 sessions about auth turned into an 84-line wiki page. 73 sessions about devcontainers got a summary I'd never have sat down to write. Four examples of what pks brain produces when you let it read half a year of your own work.
- 03The graph was there all alongPks brain ingest didn't produce a log. It produced a graph. Four nodes, three edges, and a join axis I couldn't see until product-cli showed me what a typed DAG looks like elsewhere. The 3rd post on how the AI brain is wired under the hood.
- 04From changed files to commit messagesPks brain commit-plan runs the graph's reverse query: take the staged files, find the prompts that drove each change, return a grouped plan. The 4th and final post in the series shows how it became a /commit-message skill — and why it was useless until we moved the planner from raw-JSONL scanner to firehose-direct-read.



