Prior version (v2) (2026-06-10, "Prompt-framing + footer cleanup")
This is an archived prior version of this post. The current version may have changed. Read the current version →
Mirrors the Danish v3: the 'realisation came from you' framing (reader-as-Poul aside) replaced with plain I-voice and the heading renamed to 'came from a prompt'; the hand-written 'Next post' section folded into the closing paragraph — series_footer owns the next-link.
The graph was there all along
Pks brain ingest didn't produce a log. It produced a graph. Four nodes, three edges, and a join axis I couldn't see until product-cli showed me what a typed DAG looks like elsewhere. The 3rd post on how the AI brain is wired under the hood.
When I started pks brain on May 14th I didn't have a graph in my head. I had four JSONL files. It took me a couple of weeks to see they were the same thing.
This is the 3rd post in the series about pks brain. The first one covered why the brain exists; the second showed what it produces. I realised a couple of weeks in that the pipeline was a graph — just not one I'd been calling that. This post is what I saw when I finally opened my eyes.
The realisation came from a prompt
I was in a session, still thinking we were building one thing. Then I wrote this prompt:
That's the prompt that forced this article into existence. Until then I thought we were building one thing: "a background agent that crunches sessions." That prompt split it into two: the ingest layer (deterministic firehose dump) and the graph layer (linking the entities). The latter already existed — as a by-product of the former. I just hadn't seen it.
Four nodes, three edges
The DAG pks brain produces has exactly four node types:
- Session — one Claude Code session, identified by UUID. Lives as a JSONL file at
~/.claude/projects/<project>/<uuid>.jsonl. - Prompt — one user prompt inside a session. Text, timestamp, optional slash-command.
- ToolCall — one tool invocation driven by a prompt. Tool name, duration, error flag, parent assistant UUID.
- File — one file touched by a ToolCall. Path, op (
read/write/edit/multi-edit), success flag.
Between them, three directed edges:
Session ──contains──→ PromptPrompt ──drove──→ ToolCallToolCall ──wrote/edited/read──→ File
Visually, it's the structure from the first post — worth keeping in view:
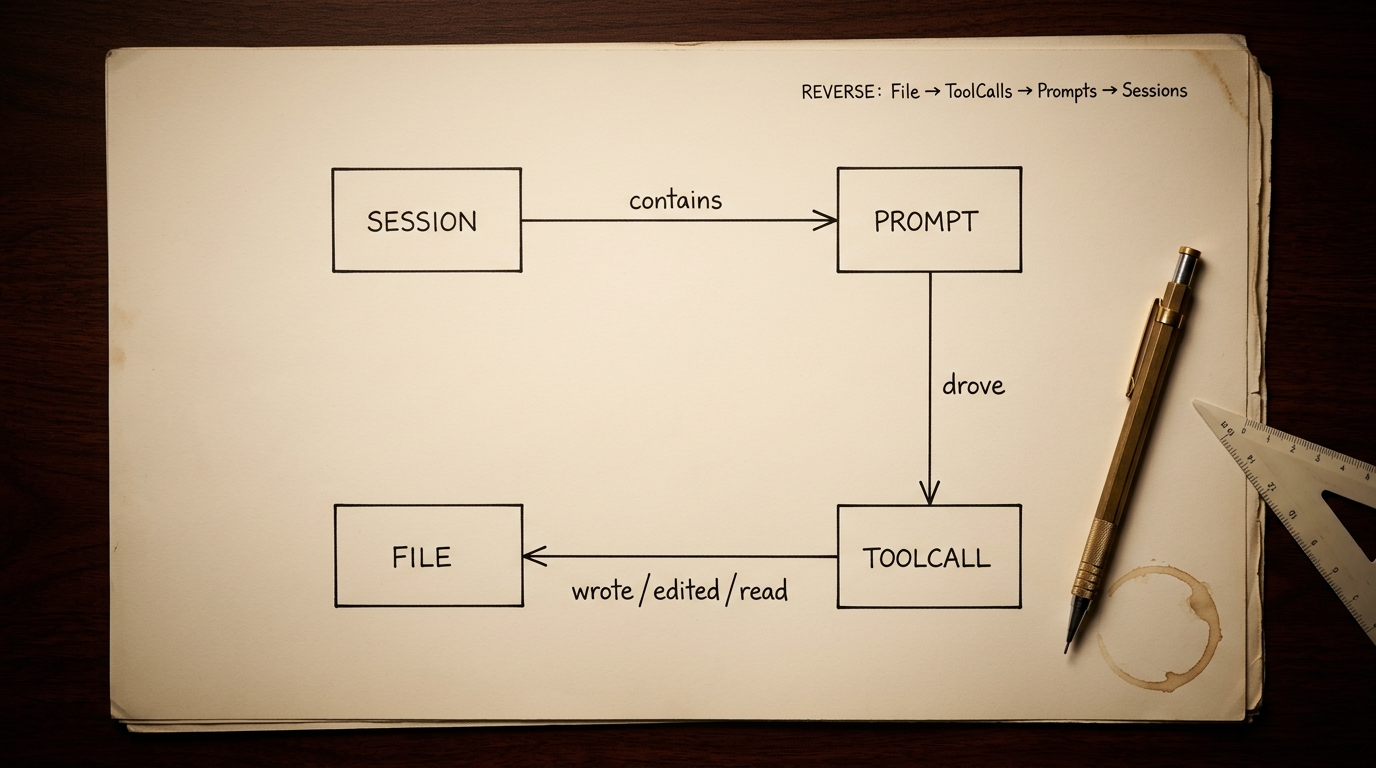
It's a DAG — every edge points downward, no cycles. That's what makes queries predictable; I never have to worry that a File lookup will loop back to itself.
Firehose rows are edges in disguise as table rows
The ingest phase produces four JSONL files in ~/.pks-cli/brain/. Each row looks like a database table row. But each row is also implicitly an edge in the graph:
prompts.jsonl — one row per user prompt. Represents both the Prompt node and its in edge to Session:
{
"sessionId": "1a475348-b3f7-4038-8256-2f364859c3d2",
"projectSlug": "-workspaces-agentic-live-www--...",
"timestampUtc": "2026-04-06T15:28:44.458Z",
"promptId": "0c2762b1-7e6f-45bd-8372-7b499b8a6edd",
"uuid": "85993c63-296b-4d22-a029-9ddacb9a9db5",
"text": "Project: pks-agent-inbox\nan email inbox for agents\n\nScope: scarfold\n\n...",
"textHash": "d39524e8cbdf3c4c",
"cwd": "/workspaces/agentic-live-www/.agentics/_work/...",
"gitBranch": "task/mnmzxlux-85f5wh",
"length": 1901,
"isSlash": false
}
tools.jsonl — one row per tool invocation. Represents the ToolCall node plus the from edge to Prompt (via parentAssistantUuid):
{
"sessionId": "agent-a6e61f715b03161e3",
"projectSlug": "-tmp-pks-runner-jobs-...",
"timestampUtc": "2026-04-12T15:40:17.614Z",
"toolName": "Glob",
"toolUseId": "toolu_014X92w1RkizWovUjbToPuTf",
"inputDigest": "f7361c8f7acae6c4",
"inputPreview": "{\"pattern\":\"/tmp/pks-runner-jobs/.../**/*\"}",
"parentAssistantUuid": "c0c06cbd-5884-4885-85bb-5d27f47348f0",
"durationMs": 16,
"isError": false,
"resultSize": 1217,
"isMcp": false,
"isSubagent": false
}
files.jsonl — one row per file operation. Represents both the File node and the wrote/edited/read edge from ToolCall:
{
"sessionId": "agent-a6e61f715b03161e3",
"projectSlug": "-tmp-pks-runner-jobs-...",
"timestampUtc": "2026-04-12T15:45:18.075Z",
"op": "write",
"filePath": "/tmp/pks-runner-jobs/.../design-system/components.md",
"success": true
}
errors.jsonl — error events attached to ToolCall nodes. Not a separate node type, more an attribute set for ToolCalls that failed.
The join is free because there's a timestamp
The interesting bit is that the four firehoses have no explicit foreign keys between them. They just share (sessionId, timestampUtc). That makes the "I have a file → find the prompt that drove the write" query trivial: filter files.jsonl on filePath → for each matched row filter prompts.jsonl on (sessionId, timestampUtc ≤ fileTs) and take the latest prompt before the edit.
That's exactly what pks brain commit-plan runs in the 4th post — without instantiating graph objects, without building an adjacency array. Just a JSONL stream and a binary search.
Deterministic vs. AI-synthesised
Ingest runs in 1–2 seconds because there's no model in the loop. It reads session JSONL files, extracts fields, writes rows — 100% deterministic. That's deliberate: I want to be able to recompute the entire firehose without spending a token.
On top of the deterministic graph sit two AI layers:
- extract — per session, the model generates a markdown summary based on
prompts.jsonl + tools.jsonl + files.jsonlfiltered to that one session. Output lands at.pks/brain/extracts/<sessionId>.md. - synth + wiki — clusters sessions by theme (using extract texts + file-path patterns + tool histories) and synthesises one wiki page per cluster. Output lands at
.pks/brain/wiki/<theme>.md.
The reason I keep them separate: the deterministic part I can re-run for free, as often as I want. The AI layer costs tokens, and it's interpretation — not truth. If the brain-extract skill changes, I can re-run extracts without touching ingest. And if ingest is broken, I see it immediately instead of discovering it via a wiki that lies convincingly.
Why it's a DAG and not "just" a table
I actually considered flattening all four firehoses into one wide table: (session_id, prompt_id, tool_call_id, file_path, timestamp). That would work for most queries.
But the brain isn't just current state. It's a timestamp per edge, and edges arrive interleaved — one prompt writes one file first, then another, then a tool call that writes nothing, then another file edit. Treating it as a flat table would shred the sequence between events — which prompt triggered which specific file edit. The DAG model says explicitly: the ToolCall → File edge has a timestamp close to the ToolCall, and the Prompt → ToolCall edge has a timestamp on the Prompt. It's the sequence that makes the commit-plan query in the 4th post possible — staged files in, reverse query over the graph, commit messages out.