Prior version (v2) (2026-05-27, "Number-first lede")
This is an archived prior version of this post. The current version may have changed. Read the current version →
Replaced the meta-narrative opener ('I started the session looking for an old conversation…') with a number-first lede: '52 staged files. 200 seconds. […] dropped to 1.3.' Same move that lifted post 1 from Hook 2 to Hook 4. Verbatim humanprompts preserved, just demoted to context after the punchline.
From changed files to commit messages
Pks brain commit-plan runs the graph's reverse query: take the staged files, find the prompts that drove each change, return a grouped plan. The 4th and final post in the series shows how it became a /commit-message skill — and why it was useless until we moved the planner from raw-JSONL scanner to firehose-direct-read.
52 staged files. 200 seconds. Three minutes of waiting on a commit message — long enough that I open another tab and forget what I was doing. When pks brain commit-plan started reading the graph directly instead of re-parsing raw JSONL on every call, the 200 seconds dropped to 1.3. A ~165× speedup. It turned the /commit-message skill from "too slow to use" into "run it every time".
This is the 4th and final post in the series about pks brain (after why the brain exists, what it produces and how the graph is wired). It's about closing the loop: take the graph post 3 established, run its reverse query against staged files, and use the result to write a commit message that knows why — not just what.
The session opened with me hunting for an old conversation I'd forgotten the content of:
The brain found it. Three-day-old session, full of notes about how to link files back to the sessions and prompts that touched them. The question landed immediately:
What the skill does
/commit-message is a Claude Code skill that runs whenever you have staged files and want to write a proper commit message. The flow:
git diff --cached --name-only→ the current staged listpks brain commit-plan --files-from <list> --include-prompts --format json→ the graph's reverse querygit diff --cached→ the actual diff (what-changed)- Synthesis: subject = what (one concrete user-visible change), body = why (synthesised from the prompts that drove the edits)
- Output in Conventional Commits format so
semantic-releaseand similar can roll the commits up into release notes later
The point is that the AI brain knows the context behind each file change — not just the change itself. When the message reads feat(blog): publish coolify-destinations-pr post it's because the graph could point at the prompts that originally discussed the coolify-destinations PR — not because the model guessed a good headline from the file names.
The graph's reverse query
Post 3 established that the graph is a DAG with four nodes: Session → Prompt → ToolCall → File. Forward is trivial. Reverse is the interesting direction:
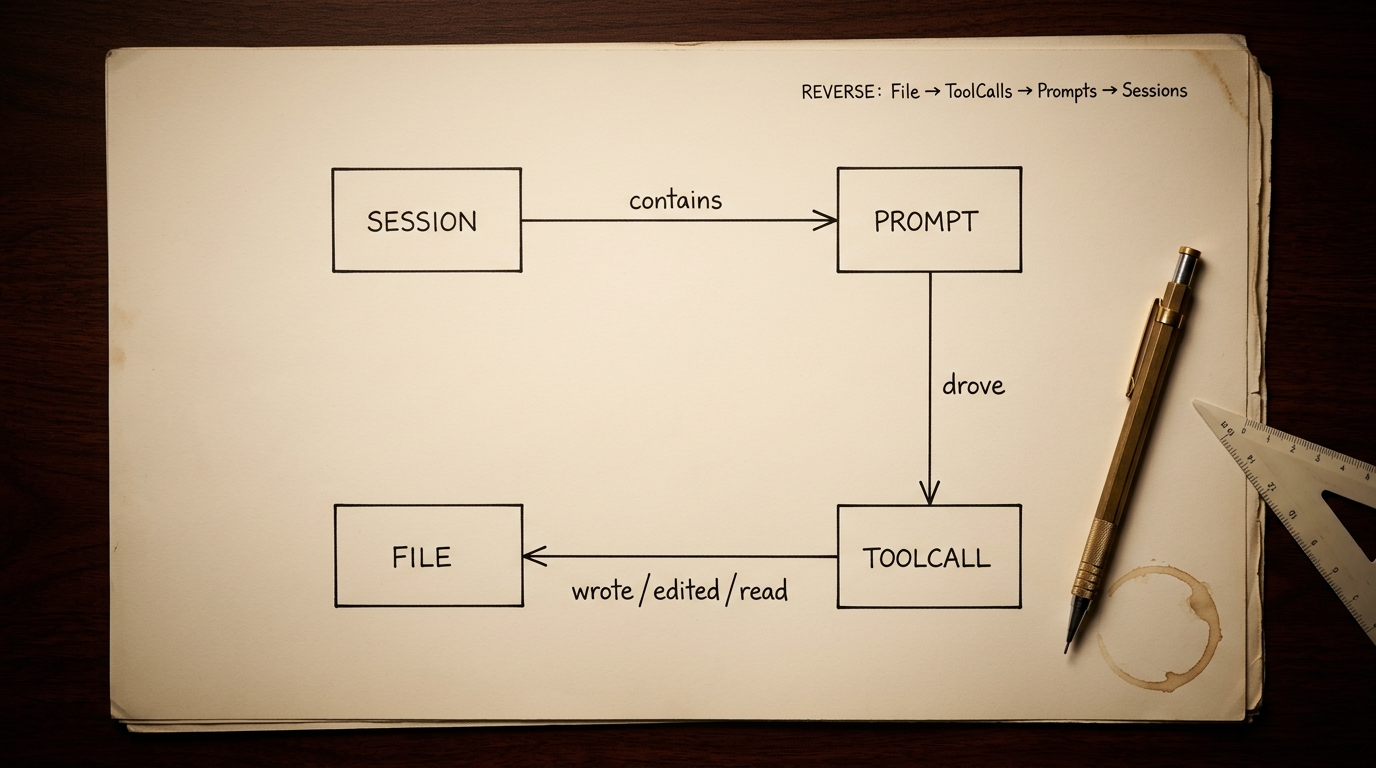
pks brain commit-plan runs exactly that reverse query: for each staged file, find ToolCalls in files.jsonl that wrote to that path; for each matched ToolCall, find the latest user prompt in prompts.jsonl with the same sessionId and timestampUtc ≤ tool-call.ts; group by primary session and return.
The result is a JSON with:
groups[]— files that belong together (same primary session)groups[i].prompts[]— the user prompts that drove edits to those files (verbatim text, timestamp)groups[i].contributing_sessions[]— other sessions that also touched the files
The skill uses that output to pick a type (feat/fix/chore/docs), a scope (the most specific area), and a subject that reflects the most user-visible change — then synthesises the body from the prompt texts without quoting them verbatim.
What made it useless first
When the skill was written, pks brain commit-plan was implemented on top of a per-file scanner that re-parsed raw ~/.claude/projects/**/*.jsonl from scratch on every call. For 52 staged files it took ~200 seconds. Three minutes. That's useless for a "press here to commit" flow.
You cut in:
That split the work into two features (exactly as post 3 describes): the ingest layer — which already produced a graph in the form of firehoses — and the graph layer, which just had to read the existing graph instead of re-parsing raw data.
The fix was a ~80-line rewrite of BrainCommitPlanner in pks-cli. Stream one pass over files.jsonl filtered to the input files, do a binary-search join against prompts.jsonl for prompts before each edit timestamp. Keep the scanner as fallback for when the firehose is absent. Add an auto-ingest before the query so the graph is fresh.
The result on the same 52-file staged set:
| Implementation | Time |
|---|---|
| Firehose grep (raw lookup over indexed firehose) | ~10 ms |
pks brain commit-plan (new — auto-ingest + firehose read) | ~1.3 s |
pks brain commit-plan (old — per-file scanner) | ~200 s |
Speedup: ~165×. It turned the skill from "too slow to use" into "run it every time".
The dogfood moment
This series was written in the session where the flip happened. This commit was written by /commit-message itself — the skill used the new firehose implementation to find the prompts that drove its own rewrite, through a 1.3-second JSON output, and synthesised:
feat(brain): wire commit-planner to firehose graph
The graph itself already existed — pks brain ingest materialises
files.jsonl as the File↔Session edge table — but BrainCommitPlanner
ignored it and re-parsed every raw ~/.claude/projects/**/*.jsonl per
input file, taking ~3 minutes for a 52-file plan. The planner now reads
the firehose directly with a binary-search join on prompts.jsonl and
keeps the scanner as fallback when the firehose is absent.
The whole chain — ingest, firehose, graph query, skill, conventional commit — closed the loop on itself. See the artifact page for /commit-message if you want to read the skill itself.
What you concretely get out of it
Three concrete things:
- Better commit messages. Subject = one user-visible change. Body = why, not what. What → the diff. Why → only visible if someone has a signal from the prompts that drove the edits. That signal didn't exist before the graph.
- Better release notes. A release pipeline (semantic-release / conventional-changelog) takes the subject list and builds "## Features" / "## Bug Fixes" automatically. Bodies survive as expandable detail. Suddenly release notes aren't a review step but a side effect.
- Traceability. Every commit can be looked up back to exactly the prompts that discussed it. That isn't an "AI wrote this" disclaimer — it's being able to read what was said before the code existed.
End of the series
That was the 4th and final post in the series about pks brain. Refresh the other three if you jumped in mid-way:
- The brain behind — why the AI brain exists at all
- A wiki written by our AI brain — what it produces
- The graph was there all along — how it's wired
Next step for me: a visualisation that renders your own pks-brain graph as an interactive DAG visualisation. If the bonus lands, it ships as post 5. If it doesn't, the series closes here — four posts, one repo, ~7,000 prompts condensed into a DAG that knows why my files exist.