Tidligere version (v2) (2026-05-27, "Korrekt DAG + drafting-illustration")
Dette er en arkiveret tidligere udgave af denne post. Den aktuelle version kan være ændret. Læs den aktuelle version →
Erstattet 'typeret knude-graf' med 'typed DAG' (calque-fix: 'typeret' og 'knude' er akademiske oversættelser, og det vi rent faktisk har er en directed acyclic graph). Byttet ASCII-diagrammet ud med en drafting-table illustration der viser den faktiske kantstruktur (Session→Prompt→ToolCall→File) uden de spurious cross-arrows tidligere udkast havde.
Hjernen bag
7.000 prompts, 88.000 tool-calls, 46.000 fil-ændringer — alt sammen liggende i ~/.claude/projects/ og aldrig læst igen. Pks brain er den stille crunchen der gør vibe-kodet kaos til ADR'er, feature-specs og søgbare wikis. Det startede som en aften i maj og blev til en DAG.
Jeg har 7.000 prompts, 88.000 tool-calls og 46.000 fil-ændringer liggende i ~/.claude/projects/ lige nu. Jeg læser aldrig nogen af dem igen. Det irriterede mig nok til at jeg byggede en hjerne der gør det for mig.
Det startede ikke som et produkt. Det startede som en sætning jeg skrev ned 14. maj fordi jeg blev træt af at glemme mine egne projekter — og fordi Andrej Karpathy lige havde postet om sit eget "second brain"-koncept og jeg ville bygge noget i den retning, bare baseret på det jeg allerede havde liggende: mine Claude Code-sessioner.
Det var det. Ingen API. Ingen schema. Ingen graf. Bare en idé om at den måde jeg faktisk arbejder på — vibe-kodet, halv-ufærdig, ti projekter åbne på én gang — kunne være input til en proces der løbende destillerede det til den slags artefakter som rigtige projekter har: ADR'er, feature-specs, en wiki, en bad-habits-rapport om mig selv.
Start vibe, go pro
Alle der har vibet sig igennem et halvt år af AI-assisteret udvikling ved det godt: man starter ALT for mange ting. De fleste dør. De få der overlever vokser fra "én aftens fjolleri" til "det her bruger jeg hver dag" uden et formelt øjeblik hvor man besluttede det.
Problemet er ikke at man mangler dokumentation. Problemet er at man har skrevet den — i Claude-sessioner, i commit messages, i halv-redigerede markdown-filer — uden at det nogensinde samles. Det bliver liggende i ~/.claude/projects/ som JSONL fra hver session, hver prompt og hvert tool-call, men i en form ingen kommer til at læse igen.
Pks brain er det forsøg på at høste den dokumentation uden at man behøver opføre sig som om man laver et "rigtigt" projekt. Du viber. Brainet cruncher i baggrunden. Når jeg åbner et projekt igen tre uger senere er der faktisk noget jeg kan læse — uden at jeg har lavet det selv.
Hvad pks brain blev til
Den oprindelige idé satte sig som fem faser, hver med sin egen kommando og sit eget checkpoint, så enhver fase kan køres for sig:
pks brain ingest → deterministisk dump af alle session-JSONL'er til
kompakte firehoses (prompts, tools, files, errors)
pks brain extract → AI-genereret markdown-resumé pr. session
(drevet af en redigerbar `brain-extract`-skill)
pks brain synth → klyngedannelse: tematiske grupper på tværs af sessions
pks brain wiki → pr.-klynge wiki-side genereret fra synthese
pks brain adr → arkitektur-klynger destilleres til ADR'er
Faserne er bevidst splittet. Den deterministiske ingest er billig og kører på 1–2 sekunder; de AI-drevne faser koster tokens og kører kun når man beder om det. pks brain refresh kæder dem sammen; resten af tiden re-render man bare den fase man har brug for.
Resultatet ligger to steder:
- Brugerens cross-project firehose under
~/.pks-cli/brain/— alle sessions på tværs af alle projekter, som én lang strøm af rækker. Det fælles maskinrum. - Projekt-lokale syntese-artefakter under
./.pks/brain/i hver git-repo — wikien, ADR'erne, feature-specs for dette projekt. Det offentlige rum hvor synthesen lander.
I dette repo har jeg lige nu omkring 7.000 prompts, 88.000 tool-calls og 46.000 fil-ændringer i firehose'en, sat i forhold til 2.940 AI-genererede session-extracts. Det er et halvt års vibe-arbejde, klar til at blive læst af en model der ikke er mig.
Vendingen: det blev en DAG
Det vidste jeg ikke 14. maj. Det viste sig først her i slutningen af maj — efter en uges arbejde med product-cli hvor en typed DAG (Feature, ADR, TC, kilde-fil) bandt arkitektur sammen — at brainet i forvejen havde produceret noget næsten identisk. Bare uden at jeg kaldte det en graf.
Hver række i files.jsonl er en kant: (session_id, tool_name, file_path, timestamp). Hver række i prompts.jsonl er en knude — den brugerprompt der drev kanterne lige bagefter. Bruger man timestamps som join-akse mellem de to firehoses, har man en File↔Session-DAG med Prompt-attribution. Gratis. Færdig udregnet. Klar til at queries.
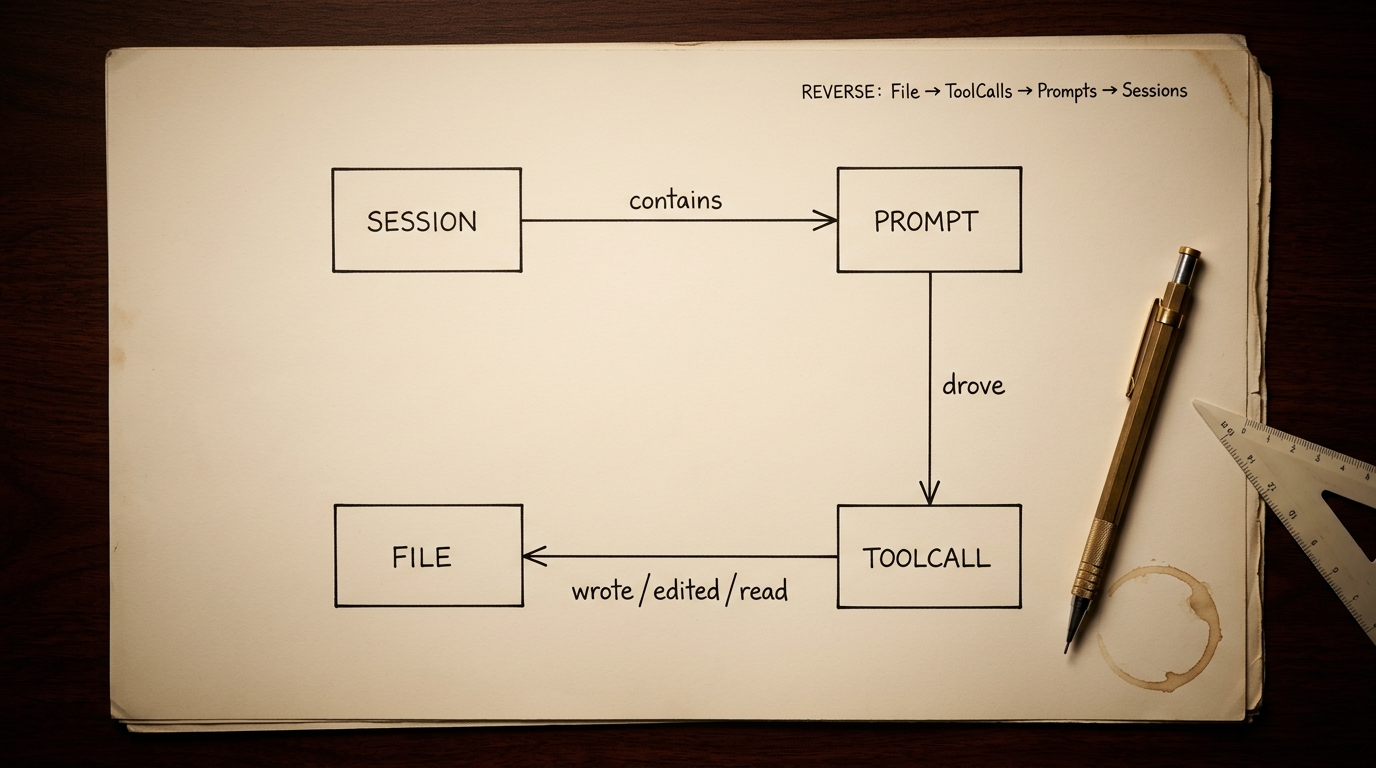
Forward er trivielt — Session indeholder en serie Prompts, hver Prompt driver et antal ToolCalls, hver ToolCall skriver/redigerer/læser en fil. Det interessante er den modsatte retning: jeg har en fil, og jeg vil vide hvad der skete med den. Reverse-queryen — File → ToolCalls → Prompts → Sessions — er hvad pks brain commit-plan kører hver gang den skal forklare en commit. Tag de staged filer, slå dem op i files.jsonl, find de prompts der drev ændringerne, returnér den grupperede plan. Det fortæller commit-message-skriveren hvorfor ændringerne skete — ikke kun hvad der er ændret.
Det 4. kapitel handler om netop det skifte: hvordan vi tog graf-laget — som lå der hele tiden, ingest-fasen byggede det på to sekunder — og brugte det til at skrive commit-messages der ved hvorfor. Da vi flyttede pks brain commit-plan fra at re-scanne rå JSONL pr. fil til at læse firehose'en direkte, gik en commit-plan over 52 staged filer fra ~200 sekunder til 1,3 sekunder. Denne post blev skrevet i den session hvor det skifte skete.
De fire kapitler
- Hjernen bag — det her indlæg. Hvorfor brainet eksisterer, hvad det består af, og hvordan DAG'en dukkede op.
- Hvad brainet faktisk ved — en turné gennem wiki-output. Hvad ser de auto-genererede sider ud som, og hvor præcise er de når man stiller en wiki-side op mod kildekoden den syntetiserer fra.
- Grafen indeni — arkitekturen i detaljer. Hvilke knuder findes der (Session, Prompt, ToolCall, File), hvilke kanter forbinder dem, hvad lagres deterministisk og hvad lagres AI-genereret.
- Fra ændrede filer til commit messages — hvordan vi joiner staged filer mod grafen for at finde de prompts der drev hver ændring, og hvordan vi bruger dem til at skrive
feat(blog): publish coolify-destinations-pr post-niveau-commit-messages automatisk. Inklusive hvorfor det først blev brugbart da grafen erstattede skanneren.
Hvem er det her for
Hvis du:
- bruger Claude Code aktivt og har en
~/.claude/projects/-mappe der vokser - savner at få noget tilbage fra det arbejde — ud over koden der allerede ligger i git
- har prøvet at "skrive ADR'er bagefter" og opdaget at det aldrig sker
… så er det her for dig. Brainet bygger ikke noget magisk. Det høster det du i forvejen har lavet, gør det søgbart, og kommer tilbage en gang om dagen og spørger om der er sket noget nyt.
Hvad har du selv liggende i ~/.claude/projects/ som du aldrig får læst igen?